Evocative Development
[print]
Mehdi Bizhani
Data @ Software
## Data @ Software === ### Data Models & Query Languages === ### Data Models - Relational Model - Edgar Codd: "Data is organized into relations (called _tables_ in SQL), where each relation is an unordered collection of tuples (_rows_ in SQL)." - **schema-on-write** - Document Model - **schema-on-read** - Graph-based Model === ### SQL vs NoSQL - Drivers for NoSQL - Greater scalability than relational databases - Specialized query operations - Dynamic and expressive data model - **Polyglot persistence** - use both SQL & NoSQL alongside === ### Sample Model (1/4) - In relational model, entities are mapped to tables - In document model, it can be contained in a JSON - The relations are **local** to _User_ entity - A user can be fetched by one query - Any `1-to-*` relation shows a tree structure 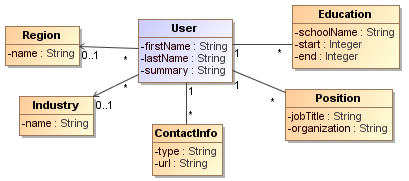 --- ### Sample Model (2/4) - We don't want to repeat _Industry_ & _Region_ (normalization) - Refactor `Education` & `Position` (adding two more `*-to-1` relations) - Now, only `Education`, `Postion`, and `ContactInfo` are _local_ to `User` 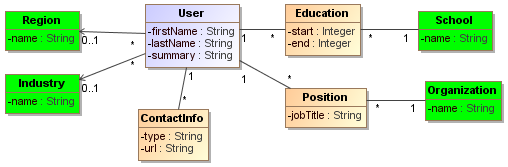 --- ### Sample Model (3/4) So in document model - `*-to-1` - Not fit nicely, need _implicit_ joins - Usually no join support, such as MongoDB, needs multiple queries (_RethinkDB_ supports) - **Data has a tendency of becoming more interconnected as features are added to applications** - `1-to-*` - Perfect - Fetched by single query --- ### Sample Model (4/4) 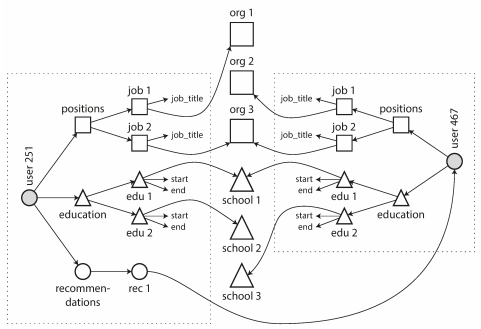 - Data within each dotted rectangle can be grouped into one document - References to _organizations_, _schools_, and other _users_ require joins when queried === #### Hierarchical vs Network Model (1/2) - Start data from a root record - Hierarchical - _CODASYL_ Model - Tree structure, every record has exactly one parent - A query in CODASYL: moving a cursor through the database by iterating over lists of records and following _access paths_ - Similar to document model: storing nested records --- #### Hierarchical vs Network Model (2/2) - Network - A record could have multiple parents - Links between records are not foreign keys === ### Data Locality - Document Model - a JSON has the data and its nested elements in one fetch - Oracle multi-table index cluster tables - Column family in the Bigtable model such as Cassandra & HBase === ### Query Languages - SQL - Declarative lang - You define _what_ to want - But _how_ to achieve the goal is up to the database system’s query optimizer - Can be executed in parallel ```sql SELECT date_trunc('month', observation_timestamp) AS observ_month, sum(num_animals) AS total_animals FROM observations WHERE family = 'Sharks' GROUP BY observ_month ``` --- ### Query Languages - MapReduce (1/3) - A programming model for processing large amounts of data in bulk across many machines - Available in MongoDB and CouchDB - `map` known as _collect_, and `reduce` known as _fold_ or _inject_ - Writing two carefully coordinated functions, which is often harder than writing a single query --- ### Query Languages - MapReduce (2/3) ```js db.observations.mapReduce( function map() { var year = this.observationTimestamp.getFullYear(); var month = this.observationTimestamp.getMonth() + 1; emit(year + "-" + month, this.numAnimals); }, function reduce(key, values) { return Array.sum(values); }, { query: { family: "Sharks" }, out: "monthlySharkReport" } ); ``` --- ### Query Languages - MapReduce (3/3) - MongoDB Solution: _aggregation pipeline_ ```js db.observations.aggregate([ { $match: { family: "Sharks" } }, { $group: { _id: { year: { $year: "$observationTimestamp" }, month: { $month: "$observationTimestamp" } }, totalAnimals: { $sum: "$numAnimals" } } } ]); ``` === ### Graph-Like Data Model - If many-to-many relationships are very common in your data - Types - Property graph model (e.g Neo4j, InfiniteGraph) - Triple-store model - Declarative query languages - Cypher - SPARQL - Datalog === ## Storage & Retrieval === ### Simple Key-Value Store ```shell # O(1) - append db_set () { echo "$1,$2" >> database } # O(n) - fetch db_get () { # 'tail -n 1' fetch latest key grep "^$1," database | sed -e "s/^$1,//" | tail -n 1 } db_set 12 '{"name":"London","attractions":["London Eye"]}' db_get 12 # OUTPUT: {"name":"London","attractions":["London Eye"]} ``` --- ### Log-file Data Store - Pros - Append-only sequence of records - Fast write data `db-set` - Cons - Slow read data `db-get`, O(n) lookup -> we should use _index_ - Large data file -> solutions are _segmentation_ & _compaction_ --- #### Segmentation, Compaction & Merge - **Segmentation** - create a new log file based on specific size limit - **Compaction** - throwing away duplicate keys with the most recent update for each key 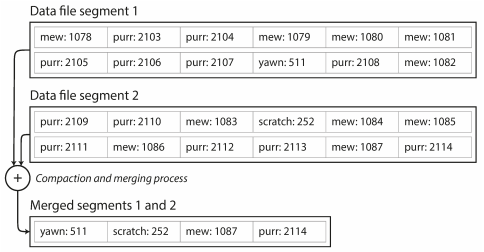 --- ### Index - Pros - **Well-chosen** indexes speed up read queries - Cons - Every index slows down writes --- ### Hash Index - Using an in-memory hash map where every key is mapped to a byte offset in the data file - Example _Bitcask_ in _Riak_ - This structure is suitable when the value for each key is updated frequently (e.g. the value is a counter) - It must fit in memory, so not suitable for very large number of keys. - Range queries are not efficient. --- ### Real Projects Issues - **File format** - using binary instead of CSV - **Deleting Records** - append the key with _tombstone_ mark, later discard on merge - **Crash recovery** - storing a snapshot of in-memory hash index on disk - **Partially written records** - using checksums to ignore corrupted data - **Concurrency control** - Only one thread to write data - Multiple threads to read concurrently === ### SSTables - **SSTable** = Sorted String Table - Store key-value pairs _sorted by key_ - Merge segment files like _mergesort_ - Same key in multiple segments, get the value from the most recent segment - No need to keep an index of all the keys in memory - Find a range in index - Scan sorted keys inside the range in the data file --- ### SSTables - Sample 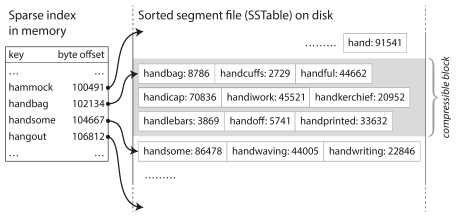 - Looking for _handiwork_ - In index, it is between _handbag_ & _handsome_ - Scan in data file inside the range --- ### SSTables - Sparse Index  - One key for every few kilobytes of segment file is sufficient - Group those records into a block and compress it before writing it to disk --- ### SSTables - Process (1/2) - On write, add record to an in-memory balanced tree, called _memtable_. - When the memtable reaches to a size limit, flush it to disk as an SSTable file as the most recent segment. - While the SSTable is being written out to disk, writes can continue to a new memtable instance. --- ### SSTables - Process (2/2) - On read, first try to find the key in the memtable, then in the most recent on-disk segment, and then older ones. - From time to time, run a merging and compaction process in the background. - To avoid crash, we can keep a separate log on disk to which every write is immediately appended not in sorted order. - The log file will be truncated after flushing the memtable to an SSTable. === ### LSM-tree - LSM-tree = Log-Structured Merge-Tree - Used in _LevelDB_ and _RocksDB_ - Storage engines based on merging and compacting of sorted files - In Lucene, mapping from term to postings list (list of IDs of all the documents) is kept in SSTable-like sorted files, which are merged in the background as needed. === ### B-Tree - Introduction - Most widely used indexing structure - Keep key-value pairs sorted by key (like _SSTable_) - Efficient for key lookup and range query - Using fixed-size blocks, called _pages_ - Read/Write one page at a time - Each page can be identified using an address or location - Always _balanced_ - _n_ keys => O(log _n_) depth --- ### B-Tree - Sample 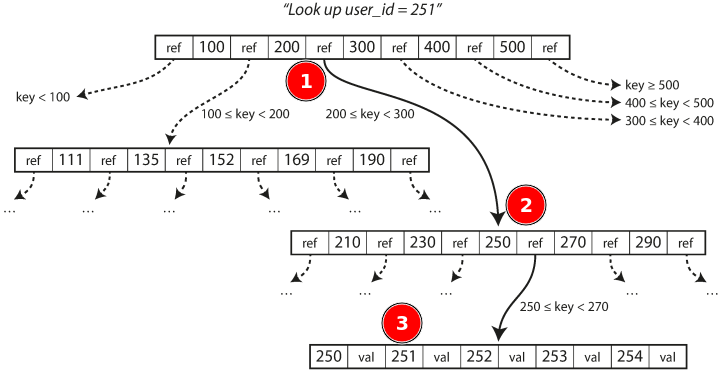 --- ### B-Tree - Lookup - Root Page - first page as the starting point - Child Page - having a continuous range of keys and reference to other children - Leaf Page - having real key-value (inline value or ref to a page contains the value) - Branching Factor - number of references in a page (in prev figure is 6) --- ### B-Tree - Update Value - Find leaf page by key - Change value for that key - Write back (replace) the modified page --- ### B-Tree - Add New Key (1/2) - Find leaf page containing the range for the new key - If there is enough space in the leaf page, add new key - Else - Split the leaf page into two half-full pages - Update parent page --- ### B-Tree - Add New Key (2/2) 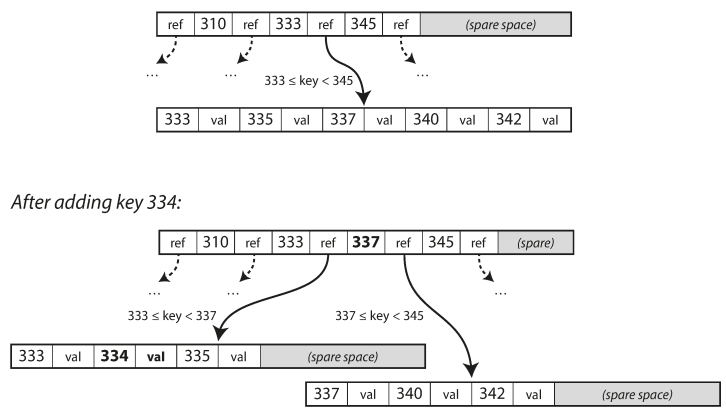 --- ### B-Tree - Reliability - Problem: database crash on rebalancing pages - Using _write-ahead log_ (_WAL_) or _redo log_ - Append-only file - Writing every B-tree modification before applying the changes to the pages of the tree itself - Careful concurrency control - Protecting the tree’s data structures with _latches_ (lightweight locks) --- ### B-Tree Optimizations